
 Opinión
Opinión
¿Realmente fallaron las encuestas electorales en EE.UU.?

El análisis de las elecciones en EE.UU. dejó varios heridos. Hillary Clinton, por ser la candidata derrotada, pero también las encuestas preelectorales; o, al menos, eso es lo que dicen, una y otra vez, diversas y variadas columnas de opinión y también notas periodísticas.
Esta condena casi universal no parece extraña, y es que las encuestas, en la fase postelectoral, no terminan de ser más que el material sacrificial que permite expiar culpas y alejar los malos espíritus; a la vez, hacer comprensible las extrañas decisiones que toman los dioses sobre nuestras mundanas elecciones. Pero este ensañamiento contra las encuestas no se asemeja a los ritos sacrificiales solo por su dinámica ritual, sino también por los criterios que se utilizan para su evaluación, criterios que en muchos casos parecen fundarse más en la intuición que en la realidad o, para ser más exacto, más en las creencias (en ocasiones asentadas por los propios medios de comunicación) que en los datos que las mismas encuestas entregan.
Por ello, parece hoy más urgente que nunca evaluar las encuestas sobre sus propios méritos y en el momento indicado. Para esto propongo observar un total de 516 encuestas preelectorales americanas (www.realclearpolitics.com), todas realizadas desde junio hasta el día antes de las elecciones.
Tomamos este rango de tiempo por dos razones. Primero, porque fue en el mes de junio cuando Clinton acepta la nominación demócrata y se convierte oficialmente en candidata a la Presidencia, y, segundo, porque es a partir de ese mes cuando comienza la verdadera “producción de encuestas preelectorales”. Así, y tal como se observa en el Gráfico N°1, los 6 meses anteriores a la elección concentran el 86% (n=534[1]) del total de encuestas registradas que, de una u otra forma, consultaban por la intención de voto entre Clinton y Trump.
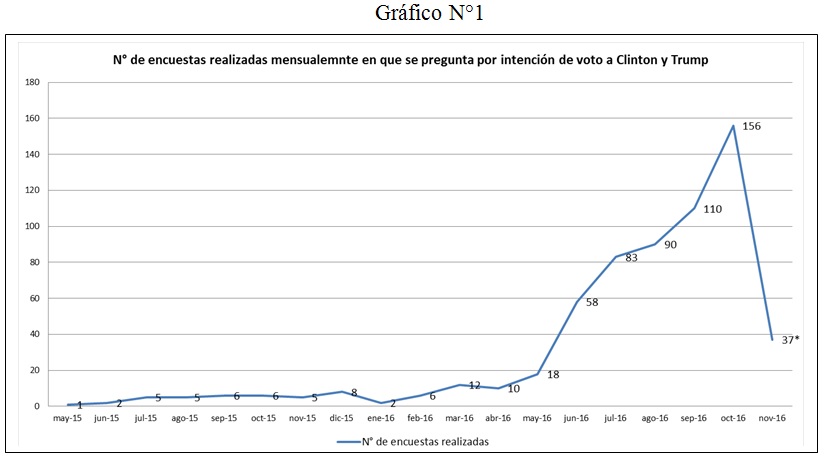
[1] La diferencia entre el total de encuestas analizadas (516) y las registradas (534) se debe a que 18 encuestas de ese total no especifican el margen de error, por lo que no pueden ser sometidas al análisis.
Fuente: elaboración propia según registros de la web www.realclearpolitics.com (Dado que la elección fue el 8 de noviembre, solo se consideran las encuestas realizadas hasta el día 7 del mismo mes).
a) Estimadores puntuales: ¿un desastre puntual?
La primera tarea a emprender es poner en evidencia hasta qué punto las encuestas acertaron respecto de los porcentajes o proporciones de votos que obtuvo finalmente cada uno(a) de los(as) candidatos(as) en las elecciones del 8 de noviembre. Para ello, una de las primeras cosas a definir es que el porcentaje de votos que las encuestas entregan a cada candidato se denomina “estimador puntual”; es decir, una asignación “exacta y específica” de los votos que posiblemente dicho candidato(a) obtendrá en la votación. Y es aquí donde encontramos el primer gran problema, ya que muchas veces estos estimadores puntuales se utilizan como si fuesen un fiel reflejo del universo que se está estudiando.
Veamos un ejemplo cualquiera, como la nota publicada por Emol el 31 de octubre de 2016 y cuyo título es “Clinton saca mínima ventaja a Trump a días de las elecciones en EE.UU.”. Fuente: Emol.com , y en donde se puede leer:
“WASHINGTON.- La candidata demócrata a la Casa Blanca, Hillary Clinton, está logrando una ventaja de entre uno y tres puntos frente a su rival republicano, Donald Trump, a pocos días de las elecciones en Estados Unidos, según dos encuestas publicadas este lunes. De acuerdo con un sondeo del diario The Washington Post y la cadena ABC News, elaborado del 25 al 28 de octubre entre 1.781 encuestados, Clinton logra un apoyo del 46%, versus un 45% de Trump.”
Una lectura rápida de esta noticia no deja dudas sobre la ventaja de Clinton; sin embargo, esto genera una grave confusión y falsas expectativas, toda vez que los porcentajes que se muestran solo representan la muestra analizada, y no a la población que se pretende estudiar. Dicho de otra forma, estos datos, tal como se presentan, no pueden ser “extrapolados”, así sin más, al universo de votantes. Para lograr esta extrapolación debemos definir un intervalo de confianza, que en su variante más básica supone simplemente sumar y restar el margen de error de la encuesta al estimador puntual (Estimador ± margen de error). Para nuestro ejemplo, el margen de error es de 2,3%, lo que supone que en el caso de la demócrata su votación a nivel poblacional o nacional puede ser cualquier porcentaje que se encuentre entre 43,7% y 48,3%. De igual forma, Trump debiese obtener como votación, en términos nacionales, algún valor entre 42,7% y 47,3%.
[cita tipo= «destaque»]Lo que se puede asentar en primer lugar es que las encuestas, antes de conocer los resultados finales, siempre mostraron, primero, un escenario de incertidumbre y, segundo, la posibilidad real de que Trump ganara en votos a nivel nacional, o en leve minoría, dada su particular y específica distribución de los votos en estados claves; tal como terminó ocurriendo. Esto no solo porque la mayor cantidad de encuestas lo afirmaba, sino también porque las diferencias cada vez se acortaban más, lo que termina por confirmar el viejo dicho hípico de que “caballo pillado, caballo ganado”.[/cita]
En este contexto, no podemos decir que Clinton adelantaba a Trump por un punto, porque los intervalos se “solapan” o se “superponen”, por lo que es igual de probable que Trump obtenga un porcentaje menor, igual o mayor que el que pudiese obtener Clinton (es lo que se llama un “empate técnico”). Y son estos equívocos de los medios y otros actores (Ej., líderes de opinión y las propias encuestadoras que se prestaron para publicar y vender rimbombantes pronósticos) los que ayudaron a sentar imágenes e ideas que eran erróneas, y que en este caso fue el instalar y reproducir la “certeza” de que Clinton tenía más posibilidades de ganar la elección cuando, en realidad, era tan probable que ganara Trump, Hillary o que empataran, es decir, la “incertidumbre en su más clara expresión”.
b) Las leyes de la hípica: caballo pillado, caballo pasado…
Un elemento complejo en la predicción de datos específicos con encuestas de opinión es que su utilidad y validez real solo es verificable una vez que se ha desarrollado la elección; es decir, podemos evaluar la fiabilidad de una predicción puntual de forma ex post. Por otro lado, debemos considerar la real naturaleza de las encuestas, en tanto producciones de fotos de ciertos momentos específicos y que, en su conjunto, definen una película del pasado (Poveda y Sánchez, 2013). Por tanto, estas encuestas son una secuencia de imágenes que se definen antes de una votación. Así, podemos y deberíamos evaluar su utilidad ex ante la elección; esto es, intentar evidenciar cómo se proyectan las votaciones, dada la tendencia que se observa a través del tiempo y antes de la elección
Además de la definición temporal, lo relevante en una carrera es conocer quién gana y quién pierde la carrera, y no tanto el tiempo que tardó el ganador y/o el perdedor; algo que Franklin (2007) define bastante bien para las encuestas cuando plantea la idea de que “en las encuestas políticas (horse-race polls) parece más interesante conocer cuál candidato va ganando (y cuál perdiendo) que la proporción exacta de votos que cada uno de ellos puede obtener”.
Por lo tanto, trataremos de evaluar las encuestas según su capacidad para indicarnos si era posible conocer un ganador o perdedor en la carrera; si esto no fuese posible, menos lo es entonces conocer por cuánto aventaja uno al otro.
Para contextualizar esto, es necesario que nos remontemos a la noche del 8 de noviembre; una noche en la que vivimos varias sensaciones. Una fue la sorpresa (por las expectativas creadas vs. la realidad) y otra fue la incertidumbre, dado lo que se vivió a nivel de votación nacional, pero sobre todo a nivel de estados.
Si bien la sorpresa vino con Florida, aunque ya había antecedentes de cambiante posición, lo realmente complejo se presentó con los estados del noreste, primero por su apretada definición, y segundo, por su constante cambio de tendencia bajo márgenes muy exiguos. Importantes son los ejemplos de Michigan, Pennsylvania o Wisconsin (46 votos electorales) que por muy pocos votos populares se adjudicaron a Trump, y para qué decir New Hampshire (4 votos electorales), que hasta altas horas de la noche estuvo bailando entre el color rojo y el azul, y que solo cerca de las 4:00 a. m. (hora local) tomó finalmente un tenue color celeste. Es decir, la incertidumbre cundía, con claridad, en 50 votos electorales, con mayor o menor dramatismo, pero siempre con mucha incerteza.
Además de lo anterior, la incertidumbre también se trasladó a nivel nacional. Así, los primeros cómputos finales que se dieron a conocer esa noche entregaban una exigua ventaja de la candidata demócrata sobre el republicano, un margen de diferencia que no iba más allá de unas decenas de miles de votos. Si bien hoy sabemos que esa ventaja se extendió a más de medio millón de votos, igualmente es una proporción marginal si lo contextualizamos en un universo de más de 120 millones de votos populares; tanto así, que esta ventaja de votos a nivel nacional no fue suficiente para que Clinton terminara ganando la elección.
Aquí la pregunta pertinente y lógica es si este escenario de incertidumbre era algo que las encuestas nos decían sí o no, y si ellas claramente nos hablaban de esta imposibilidad de conocer quién ganaría la elección, tal como nos mostró la propia realidad durante buena parte de la jornada eleccionaria. En este punto, y si vemos el Gráfico N°2, podemos observar la tendencia de dos tipos de encuestas: primero, las que reportaban que entre Clinton y Trump existía un empate técnico al existir una superposición de sus intervalos de confianza (líneas roja y azul), y, segundo, las encuestas que daban como ganador a uno de los dos candidatos, la mayor de la veces a Clinton (líneas rosada y negra).
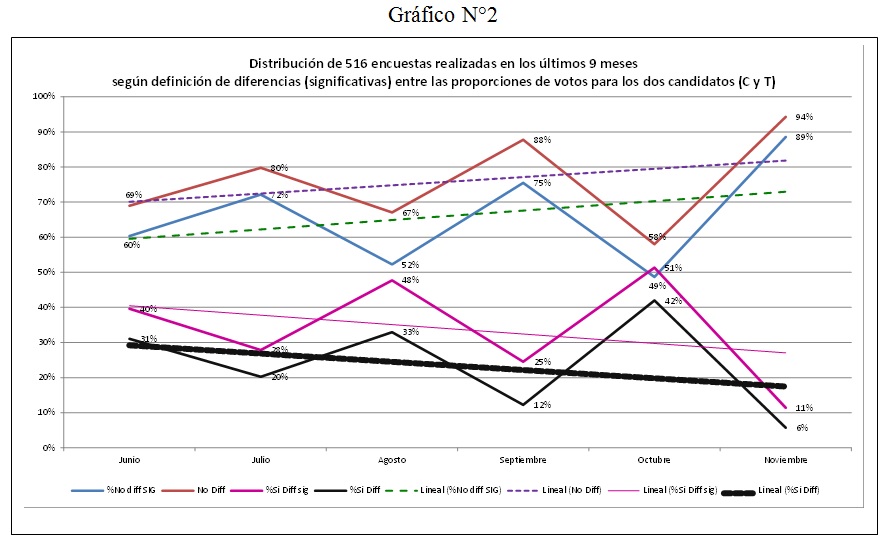
Fuente: elaboración propia según registros de la web www.realclearpolitics.com
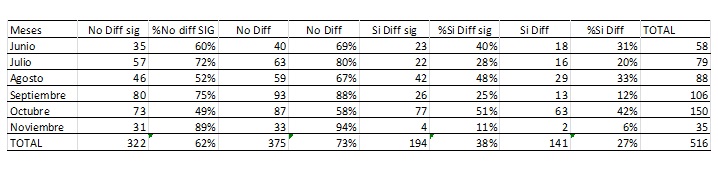
Líneas azul y rosa representan las distribuciones espejo a partir de la proporción de encuestas que en cada mes reportan diferencias estadísticamente significativas entre los intervalos de confianza de cada candidato, Clinton y Trump. La azul indica la proporción de encuestas que reportaban la no existencia de diferencias significativas entre los intervalos. Por el contrario, la línea rosada evidencia la proporción de encuestas que reportaban que sí existía una diferencia estadísticamente significativa entre los intervalos de confianza calculados para cada uno de los candidatos. Las líneas roja y negra representan el mismo análisis, y se distingue del anterior en que los intervalos son calculados solo a partir de la suma y resta (±) de los márgenes de error, definiendo así una medida de comparación menos exigente que la anterior, dado que no se evalúa ni la significancia estadística de la diferencias entre los intervalos y, tampoco, se considera que la votación de Clinton y Trump se construye bajo distribuciones polinómicas al existir más de dos candidatos en competencia u otras opciones de respuesta (Ej., indecisos).
Tal como se puede observar, la mayor parte de las analizadas, a excepción de octubre, evidenciaba que entre Clinton y Trump existía un empate técnico. A esto se debe sumar que, por un lado, la tendencia general de estas distribuciones explicitaban que el “el empate técnico” entre los candidatos era algo que iba aumentando conforme transcurrían los meses; por otro, las encuestas del último mes, que es cuando la mayor cantidad de personas define su voto, mostraban, bajo una abrumadora mayoría (con los porcentajes más altos de la serie), este final ajustado, por tanto, todos los indicadores evidenciaban que cualquier cosa era esperable.
Por el contrario, la proporción de encuestas que, dados sus intervalos de confianza, mantenían que uno de los candidatos era el ganador (por lo general Clinton) fueron siempre minoritarias respecto de las que definían el empate técnico. Con el tiempo la relevancia de estas encuestas fue disminuyendo, dando protagonismo a las encuestas que no definían a ninguno de los dos candidatos como claro ganador. En conclusión, las encuestas –de forma mayoritaria y creciente en el tiempo– indicaban que el escenario que se terminó viviendo el 8 de noviembre siempre fue el más probable.
Además de lo anterior, y si nos hubiésemos concentrado en este grupo de encuestas mayoritarias, podríamos haber constatado que las diferencias entre los intervalos se iban acortando, como si fuesen dos placas tectónicas que se van superponiendo una a la otra, tal como se evidencia en el Gráfico N°3. Así, y al igual que en el caso anterior, el empate entre los candidatos era cada vez más claro conforme pasaban los meses, por lo que el escenario de la incertidumbre se iba haciendo también cada vez más claro y evidente.
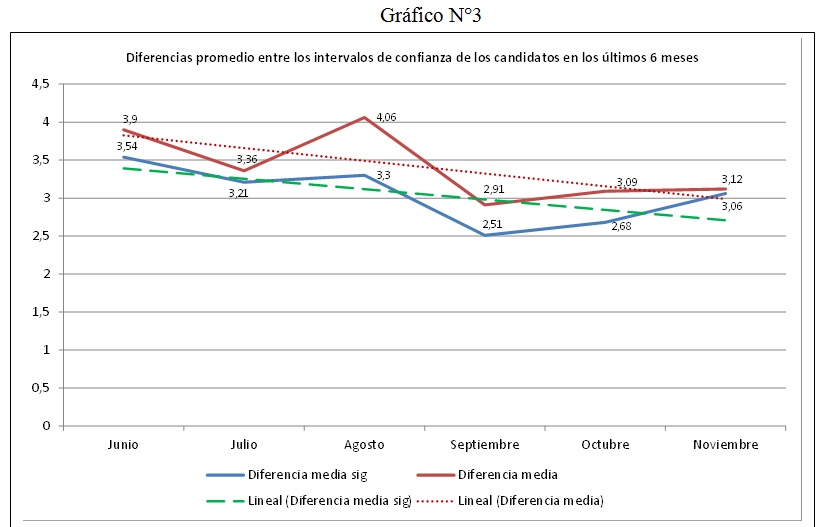
Fuente: elaboración propia según registros de la web www.realclearpolitics.com
La línea roja representa las diferencias entre los intervalos calculados de forma simple, es decir, ± el margen de error. La azul, representa la misma diferencia entre intervalos, pero esta vez calculado a partir de márgenes de error propios de encuestas polinómicas o con más de dos candidatos u opciones.
A modo de conclusión, lo que se puede asentar en primer lugar es que las encuestas, antes de conocer los resultados finales, siempre mostraron, primero, un escenario de incertidumbre y, segundo, la posibilidad real de que Trump ganara en votos a nivel nacional, o en leve minoría, dada su particular y específica distribución de los votos en estados claves; tal como terminó ocurriendo. Esto no solo porque la mayor cantidad de encuestas lo afirmaba, sino también porque las diferencias cada vez se acortaban más, lo que termina por confirmar el viejo dicho hípico de que “caballo pillado, caballo ganado”. En este caso, la predicción del dicho era muy probable si se prestaba atención a un conjunto de fotogramas que, bajo un guión plano y anunciado, entregaba el dramatismo del desenlace al particular sistema de elección norteamericano, donde un candidato que obtiene una menor cantidad de votos populares respecto de su contendor puede ser igualmente electo si la distribución de dichos votos logra ciertas ventajas a nivel distrital.
Pero la conclusión más relevante, al menos para este caso, es que a la luz de estos datos se evidencia que las encuestas no fracasaron del todo o, como mínimo, estuvieron lejos de ser un desastre. Más bien, lo desastroso fue la lectura errada (interesada o no) que se hizo de ellas. Esta lectura terminó instalando ideas y expectativas respecto de la elección, y de Clinton en particular, que no tenían mucho sustento, y el poco que tenían decrecía con el tiempo. Por lo tanto, la culpa de la incertidumbre y de la extrañeza del resultado final está lejos de ser responsabilidad de las encuestas, al menos para este caso particular.

